Concepts
Pulsar provides robust support for load balancing to ensure efficient utilization of resources across Pulsar clusters. Load balancing in Pulsar involves distributing messages and partitions evenly among brokers and consumers to prevent hotspots and optimize performance.
Before getting started with load balancing, it's important to review the key components to ensure that resources are utilized efficiently and varying workloads can be handled by the system effectively.
Brokers
In a Pulsar cluster, brokers are responsible for serving messages for different topics and partitions. Broker load balancing ensures that each broker handles a proportional share of the load.
Producers
Producers in Pulsar are responsible for publishing messages to topics. Pulsar clients (producers) connect to brokers to publish messages. Producer load balancing (i.e., connection pooling mechanism in Pulsar) ensures that producers are distributed across brokers to avoid overwhelming a single broker with too many connections.
Consumers
Consumers in Pulsar are responsible for consuming messages from topics. Depending on how consumer load balancing is configured (i.e., using exclusive or shared consumers or auto-rebalancing), you can ensure even load distribution.
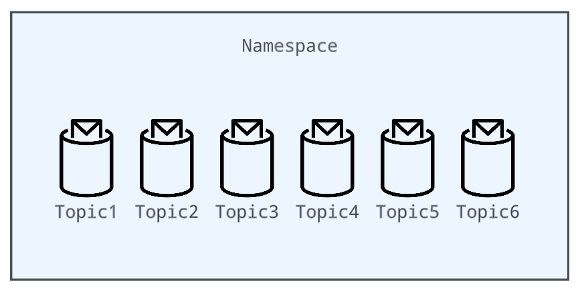
Topics
Topics are the basic units for clients to publish and consume messages. Related topics are logically grouped into a namespace. To efficiently manage metadata and keep track of all of them moving through the system, Pulsar uses a strategy of grouping topics by partitioning on a namespace to create topic bundles.
Bundles
Bundles represent a range of partitions for a particular namespace in Pulsar, comprising a portion of the overall hash range of the namespace.
Bundle is introduced in Pulsar to represent a middle-layer group. Each bundle is an assignment unit, which means topics are assigned to brokers at the bundle level rather than the topic level.
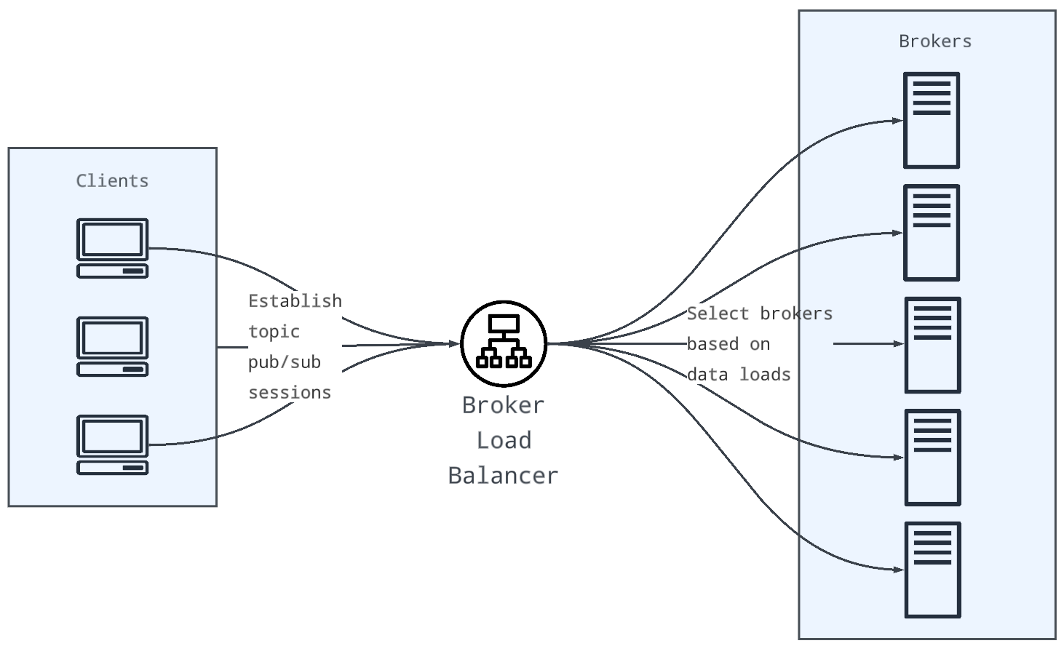
Broker load balancing
The broker load balancer component is like a "traffic cop" sitting between clients and brokers. It balances topic sessions across brokers based on dynamic load data, such as broker resource usage (e.g., CPU, memory, network IO) and topic/bundle loads (e.g., throughput).
When properly balanced, the brokers can handle increased traffic and ensure that the system can scale seamlessly to accommodate growing workloads. Load balancing helps prevent bottlenecks and ensures that the resources of the cluster are utilized optimally, leading to better throughput and reduced message processing latency.
Topic bundling
Topic bundling refers to the process of grouping topics into bundles. Pulsar organizes topics into bundles within a namespace. Each bundle is a range of partitions, and Pulsar can automatically distribute these bundles across brokers to achieve load balancing. This allows the cluster to scale more efficiently as brokers can independently manage their assigned bundles.
For example,
Topic load statistics (e.g., message rates) are aggregated at the bundle layer, which reduces the cardinality of load samples to monitor.
For dynamic topic-broker assignments, Pulsar persists these mappings at the bundle level, which decreases the space for storing dynamic topic-broker ownerships.
Pulsar allows you to dynamically scale the number of brokers, producers, and consumers to adapt to changing workloads. As brokers are added or removed, Pulsar handles the redistribution of partitions and bundles automatically.
Workflow
Below is the workflow for grouping topics into bundles.
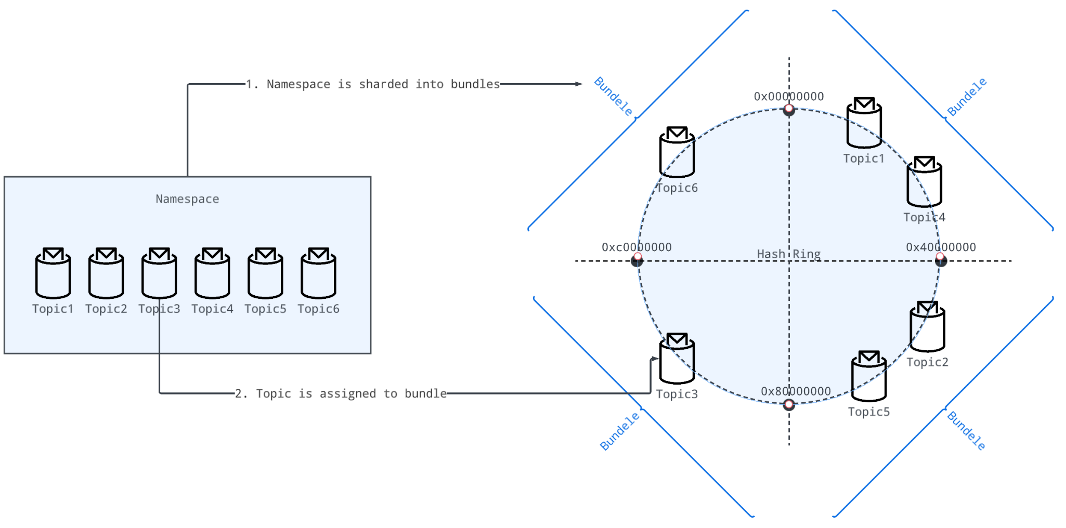
Step 1: shard namespaces into bundles
Internally, when a namespace is created, the namespace is sharded into a list of bundles.
Step 2: assign topics to bundles
When a topic is created or looked up for pub/sub sessions, brokers map the topic to a particular bundle by taking the hash of the topic name (for example, hash("my-topic") = 0x0000000F) and checking in which bundle the hash falls.
Here "topic" means either a non-partitioned topic or one partition of a partitioned topic. For partitioned topics, Pulsar internally considers partitions as separate topics, hence different partitions can be assigned to different bundles and brokers.
Bundle assignment
Bundle assignment refers to assigning bundles to brokers dynamically based on changing conditions.
For example, based on broker resource usage (e.g., CPU, memory, network IO) and bundle loads (e.g., throughput), a bundle is dynamically assigned to a particular broker. Each bundle is independent of the others and thus is independently assigned to different brokers. Each broker takes ownership of a bundle (aka, a subset of the topics for a namespace).
Bundle assignment plays a crucial role in achieving efficient load distribution and scalability within a Pulsar cluster. The purpose of bundle assignments is to ensure balanced resource utilization and facilitate dynamic scaling within the Pulsar architecture.
Workflow
Below is the workflow for dynamic bundle assignment.
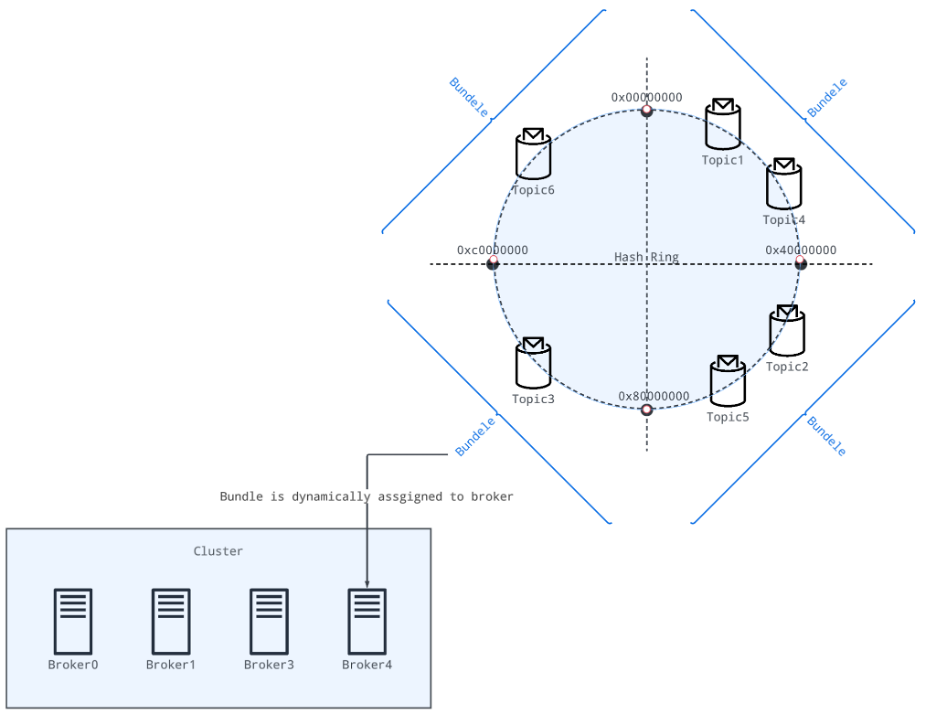
Step 1: assign bundles to brokers dynamically
When a client starts using new topics (bundles) that are not assigned to any broker, a process is triggered to choose the best-suited broker to acquire ownership of these bundles according to the load conditions.
Step 2: reassign bundles to other brokers (optional)
If a broker owning a bundle crashes, the bundle (topic) is reassigned to another available broker.
To discover the current bundle-broker ownership for a given topic, Pulsar uses a server-side discovery mechanism that redirects clients to the owner brokers' URLs. This discovery logic requires:
Bundle key ranges for a given namespace, to map a topic to a bundle.
Bundle-broker ownership mapping, to direct the client to the current owner or to trigger a new ownership acquisition in case there is no broker assigned.
All bundle ranges and broker-bundle ownership mappings are stored in a metadata space, and brokers look up them when clients try to discover owner brokers. For performance reasons, these data are cached at the broker in-memory layer too.
Bundle splitting
Bundle splitting refers to the process of identifying and splitting overloaded bundles, which helps reduce hot spots, achieve more granular load balancing, improve resource utilization, and enable finer-grained horizontal scaling within the Pulsar cluster.
The bundle splitting process involves breaking down the original bundle into smaller bundles, each containing a subset of the original partitions. This allows for better distribution of the message and processing load across brokers in the cluster.
You can split bundles in the following ways:
Automatic: enable Pulsar's automatic bundle splitting process when a namespace has a significant increase in workload or the number of partitions exceeds the optimal capacity for a single bundle.
Manual: trigger bundle splitting manually, to divide an existing bundle into multiple smaller bundles.
| Bundle splitting methods | Definition | When to use |
|---|---|---|
| Automatic | Bundles are split automatically based on different bundle splitting algorithms. | Automatic bundle splitting is most commonly used. You can use this method in various scenarios, such as when a bundle remains hot for a long time. |
| Manual | Bundles are split manually based on specified positions. | Manual bundle splitting serves as a supplementary approach to automatic bundle splitting. You can use this method in various scenarios, such as: - If automatic bundle splitting is enabled, but there are still bundles that remain hot for a long time. - If you want to split bundles and redistribute traffic evenly before having any broker overloaded. |
Workflow
Below is the workflow for splitting bundles automatically or manually.
- Automatic bundle splitting
- Manual bundle splitting
Step 1: find target bundles
If the auto bundle split is enabled,
For the modular load balancer, the leader broker will check if any bundle's load is beyond the threshold.
For the extensible load balancer, the load manager will check the bundle's load in each owner broker.
Bundle splitting threshold can be set based on various conditions. Any existing bundle that exceeds any of the thresholds is a candidate to be split. The load balancer assigns the newly split bundles to other brokers, to facilitate the traffic distribution.
For how to enable bundle split and set bundle split thresholds automatically, see TBD (the docs is WIP, stay tuned!).
Step 2: compute bundle splitting boundaries
Now the target bundles which need to be split are found. Before splitting, the owner broker needs to compute the splitting positions based on bundle splitting algorithms.
Step 3: split bundles by boundaries
Now the owner broker starts splitting the target bundles and then repartition them.
After the split, the owner broker updates the bundle ownerships and ranges in the metadata space. The newly split bundles can be automatically unloaded from the owner broker.
For example, if the bundle partition is [0x0000, 0x8000, 0xFFFF], and the splitting boundary is [0x4000] on the target bundle range, [0x0000, 0x8000).
Then the bundle partitions after split is [0x0000, 0x4000, 0x8000, 0xFFFF].
Then the bundle ranges after split is [0x0000, 0x4000), [0x4000, 0x8000), and [0x8000, 0xFFFF].
Step 1: find target bundles
Based on the broker resource usage (for example, the number of topics or sessions, message rates, or bandwidth), you can choose a hot bundle to split.
Step 2: compute bundle splitting position boundaries
If you want to use the specified_positions_divide algorithm, you need to specify a splitting boundary.
If you want to use other bundle splitting algorithms except for the specified_positions_divide algorithm, those algorithms will calculate the position automatically.
Step 3: split bundles at the specific boundaries from step 2.
For how to split bundles manually, see TBD (the docs is WIP, stay tuned!).
Bundle splitting algorithms
Bundle splitting positions can be calculated using different bundle splitting algorithms.
Below is a brief summary of bundle splitting algorithms.
| Bundle splitting algorithm | Definition | When to use | Available in automatic or manual method? | Available version |
|---|---|---|---|---|
| range_equally_divide | Split a bundle into two parts with the same hash range size. | This is the default bundle splitting algorithm. Use when there are a large number of topics. | - Automatic - Manual | Pulsar 1.7 and later versions |
| topic_count_equally_divide | Split a bundle into two parts with the same number of topics. | Use when there are a small number of topics. | - Automatic - Manual | Pulsar 2.6 and later versions |
| specified_positions_divide | Split a bundle into several parts by the specified positions. | Use when the automatic bundle splitting is turned off, or a bundle is not split even if the automatic bundle splitting is turned on. Note: Be cautious when using this algorithm. For example, if bundles are split into too many small parts, then these bundles could not be hit by the hash key. Currently, bundle compaction is not supported. | - Manual | Pulsar 2.11 and later versions |
| flow_or_qps_equally_divide | Split a bundle into several parts based on message rate and throughput. | Use when splitting bundles proportional to traffic. | - Automatic - Manual | Pulsar 3.0 and later versions |
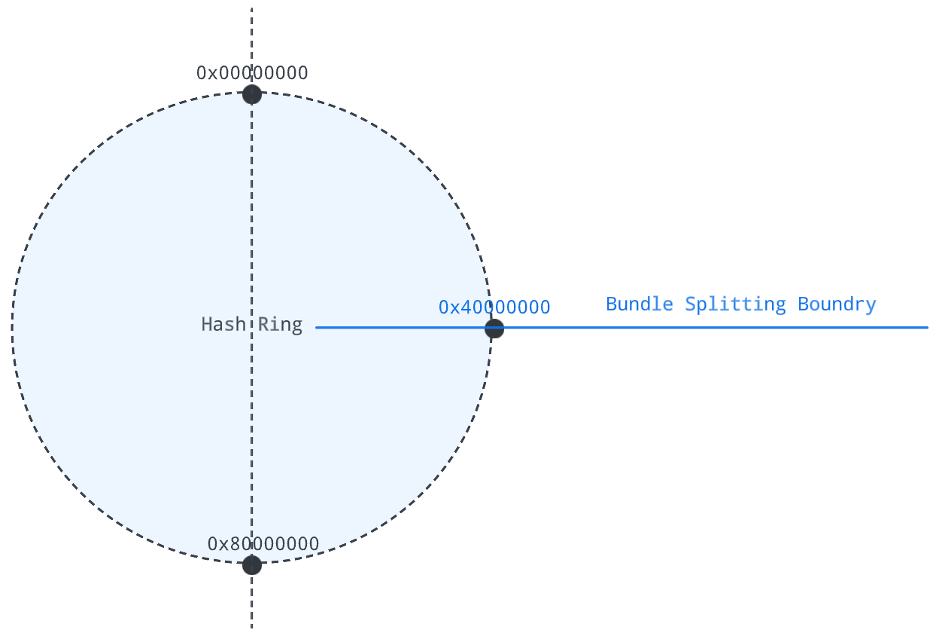
range_equally_divide
range_equally_divide splits a bundle into two parts with the same hash range size.
For example, if the target bundle to split is (0x00000000, 0x80000000), then the bundle split boundary is [0x40000000].
topic_count_equally_divide
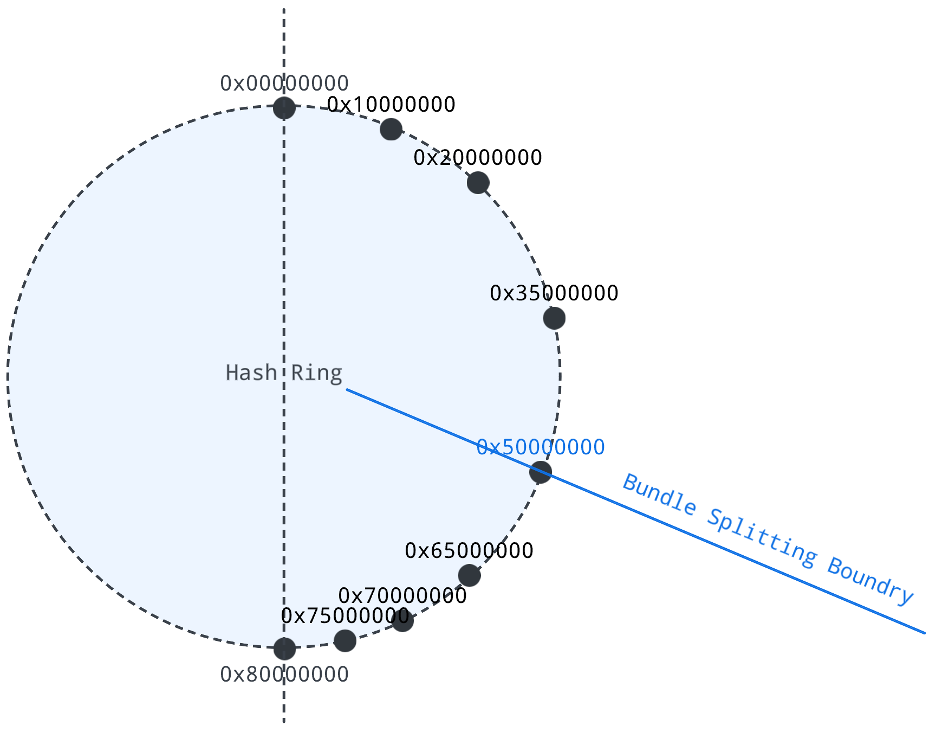
topic_count_equally_divide splits a bundle into two parts with the same number of topics.
For example, if there are 6 topics in the target bundle [0x00000000, 0x80000000), then you can set the bundle splitting boundary at 0x50000000 to make the left and right sides of the number of topics the same.
hash(topic1) = 0x10000000
hash(topic2) = 0x20000000
hash(topic3) = 0x35000000
hash(topic4) = 0x65000000
hash(topic5) = 0x70000000
hash(topic6) = 0x75000000
That is, the target bundle to split is [0x00000000, 0x80000000), and the bundle split boundary is [0x50000000].
For implementation details, see PR-6241: support evenly distribute topics count when splitting bundles.
specified_positions_divide
specified_positions_divide splits bundles into several parts by specified positions.
For example, if you have 2 large topics and there are on the same bundle. Topic1 is at 0x30000000, topic2 is at 0x35000000, and the bundle range is [0x00000000, 0x40000000), then you can set the bundle split boundary as 0x33000000.
For implementation details, see PIP-143: support split bundle by specified boundaries.
flow_or_qps_equally_divide
flow_or_qps_equally_divide splits bundles into several parts based on message rate (controlled by loadBalancerNamespaceBundleMaxMsgRate) or message throughput (controlled by loadBalancerNamespaceBundleMaxBandwidthMbytes). The split position is determined by reaching the threshold of either message rate or message throughput.
For example, suppose that you have 6 topics on a bundle range [0x00000000 to 0x80000000] as below.
| Topic name | Hash code | Message rate | Message throughput |
|---|---|---|---|
| t1 | 0x10000000 | 100/s | 10M/s |
| t2 | 0x15000000 | 200/s | 20M/s |
| t3 | 0x24000000 | 300/s | 30M/s |
| t4 | 0x39000000 | 400/s | 40M/s |
| t5 | 0x58000000 | 500/s | 50M/s |
| t6 | 0x76000000 | 600/s | 60M/s |
The split position varies depending on the values of message rate or message throughput.
Case 1: split position is determined by message rate as it reaches the threshold earlier
If you set
loadBalancerNamespaceBundleMaxMsgRate=450/s
loadBalancerNamespaceBundleMaxBandwidthMbytes=200M/s
Since
100/s+ 200/s < 450/s
100/s+ 200/s + 300/s > 450/s
So the split boundary is between t2 and t3, that is:
splitStartPosition = 0x15000000
splitEndPosition = 0x24000000
splitPosition = (0x15000000 + 0x24000000) / 2 = 0x19500000
Note that the bundle split will be continued as below:
------ 2nd bundle splitting ------
Since
300/s < 450/s
300/s + 400/s > 450/s
So the split boundary is between t3 and t4, that is
splitStartPosition = 0x24000000
splitEndPosition = 0x39000000
splitPosition = 31500000 = (0x24000000 + 0x39000000) / 2
------ 3rd bundle splitting ------
Since
400/s < 450/s
400/s + 500/s > 450/s
So the split boundary is between t4 and t5, that is
splitStartPosition = 0x39000000
splitEndPosition = 0x58000000
splitPosition = 48500000 = (0x39000000 + 0x58000000) /2
------ 4th bundle splitting ------
Since
500/s > 450/s
600/s > 450/s
So the split boundary is between t5 and t6, that is
splitStartPosition = 0x58000000
splitEndPosition = 0x76000000
splitPosition = 67000000 = (0x58000000 + 0x76000000) / 2
Case 2: split position is determined by message throughput as it reaches the threshold earlier
If you set
loadBalancerNamespaceBundleMaxMsgRate=1900/s
loadBalancerNamespaceBundleMaxBandwidthMbytes=90M/s
Since
10M/s+ 20M/s + 30M/s < 90M/s
10M/s+ 20M/s + 30M/s + 40M/s > 90M/s
So the split boundary is between t3 and t4, that is:
splitStartPosition = 0x24000000
splitEndPosition = 0x39000000
splitPosition = (0x24000000 + 0x39000000) / 2 = 0x31500000
Note that the bundle split will be continued:
------ 2nd bundle splitting ------
Since
40 + 50 ≤ 90
40 +50 + 60 > 90
So the split boundary is between t5 and t6, that is:
splitStartPosition = 0x58000000
splitEndPosition = 0x76000000
splitPosition = (0x58000000 + 0x0x76000000) / 2 = 0x67000000
Case 3: split position is determined by both message rate and message throughput as they reach the thresholds at the same time
If you set
loadBalancerNamespaceBundleMaxMsgRate=1100
loadBalancerNamespaceBundleMaxBandwidthMbytes=110
From the message rate side:
Since
100/s+ 200/s + 300/s + 400/s < 1100/s
100/s+ 200/s + 300/s + 400/s + 500/s > 1100/s
So the split boundary is between t4 and t5, that is:
splitStartPosition = 0x39000000
splitEndPosition = 0x58000000
splitPosition = (0x39000000 + 0x58000000) / 2 = 0x48500000
From the message throughput side:
Since
10M/s+ 20M/s + 30M/s + 40M/s < 110M/s
0M/s+ 20M/s + 30M/s + 40M/s + 50M/s > 110M/s
So the split boundary is between t4 and t5, that is:
splitStartPosition = 0x39000000
splitEndPosition = 0x58000000
splitPosition = (0x39000000 + 0x58000000) / 2 = 0x48500000
In summary, the split position is 0x48500000.
For implementation details, see PIP-169: support split bundle by flow or QPS.
Bundle unloading
Bundle unloading (shedding) refers to the process of closing bundles (topics), releasing ownership, and reassigning bundles (topics) to a less-loaded broker from overloaded brokers, based on load conditions.
Bundle unloading balances the workload across brokers and optimizes resource utilization in the cluster. For example, when a Pulsar cluster experiences changing workloads or scaling events (e.g., adding or removing brokers), bundle unloading ensures that the partitions are evenly distributed and no broker becomes overloaded.
You can unload bundles in the following ways:
Automatic: enable Pulsar's automatic bundle unloading process when a broker is overloaded.
Manual: trigger bundle splitting manually, to unload a bundle from one broker to another broker within a Pulsar cluster.
| Bundle unloading methods | Definition | When to use |
|---|---|---|
| Automatic | When the load balancer recognizes a particular broker is overloaded, it forcefully unloads some bundles' traffic from the overloaded broker, so that the unloaded bundles (topics) can be reassigned to less-loaded brokers by the assignment process. | Use when there is fluctuating traffic that varies over time. |
| Manual | You can manually trigger bundle unloading at any time. | Manual bundle unloading serves as a supplementary approach to automatic bundle unloading. If the automatic unloading does not kick in (e.g., due to misconfiguration), you can trigger manual unloading to mitigate the load-imbalance issue. To avoid manual unload operations, you need to correctly tune load balance configs according to the cluster's traffic. |
Workflow
Below is the workflow for unloading bundles automatically or manually.
- Automatic bundle unloading
- Manual bundle unloading
Step 1: find target brokers
With the broker load information collected from all brokers, the leader broker computes the resource usage of each broker based on the bundle unloading strategies.
Step 2: unload bundles
If the lead broker finds a broker is overloaded, it will calculate the overloaded bundles, ask the overloaded broker to unload some bundles of topics, remove the target bundles' ownerships, and close the topic sessions and the client connections.
Step 3: assign new owners
The unloaded bundles are assigned to less loaded brokers, and the clients connect to them.
For the modular load balancer, bundles will be post-assigned to available brokers when clients send lookup requests.
For the extensible load balancer, bundles will be pre-assigned to available brokers when unloading.
When unloading happens, the client experiences a small latency blip while the topic is reassigned.
For how to unload bundles automatically, see TBD (the docs is WIP, stay tuned!).
Step 1: find target bundles
Based on the broker resource usage (for example, CPU, network, and memory usage), you can choose hot bundles to unload.
Step 2: unload hot bundles
Unload hot bundles to available brokers. Target bundles' ownerships will be transferred, and topic connections will be closed.
For how to unload bundles manually, see TBD (the docs is WIP, stay tuned!).
Bundle unloading strategies
You can choose different bundle unloading strategies based on your needs.
Below is a quick summary of bundle unloading strategies, which are only applicable for unloading bundles automatically.
| Bundle unloading strategy | Definition | When to use | Available version |
|---|---|---|---|
| OverloadShedder | Unload bundles on brokers if a broker's maximum resource usage exceeds the configured threshold. | Use when you want to set broker usage below a threshold. | Pulsar 1.18 and later versions. This strategy is only available in the modular load balancer. |
| ThresholdShedder | Unload bundles if a broker's average usage is greater than the cluster average usage plus configured threshold. | Use when you want to evenly spread loads across all brokers base on cluster average usage. | Pulsar 2.6 and later versions. This strategy is only available in the modular load balancer. |
| UniformLoadShedder | Distribute load uniformly across all brokers, based on minimal and maximum load. | Use when you want to compare the minimal and maximum loaded brokers. | Pulsar 2.10.0 and later versions. This strategy is only available in the modular load balancer. |
| TransferShedder | Unload bundles from the highest load brokers to the lowest load brokers until the standard deviation of the broker load distribution is below the configured threshold. | This is the default strategy for the extensible load balancer. It pre-assigns destination brokers when unloading. | Pulsar 3.0 and later versions. This strategy is only available in the extensible load balancer. |
OverloadShedder
OverloadShedder strategy sheds bundles on brokers if a broker's maximum resource usage exceeds the configured threshold (loadBalancerBrokerOverloadedThresholdPercentage).

If a broker is overloaded and has at least two bundles assigned. At the same time, if that broker has at least one bundle that has not been unloaded, then this (these) bundle(s) will be unloaded. Bundles with higher message throughput will be unloaded before those with lower message throughput.
The determination of when a broker is overloaded is based on the threshold of CPU, network, and memory usage. Whenever either of those metrics reaches the threshold (the default value is 85%), the system triggers the bundle unloading.
ThresholdShedder
ThresholdShedder strategy sheds the bundles if a broker's average usage is greater than the cluster average usage plus configured threshold.

Workflow
ThresholdShedder first computes the average resource usage of brokers for the whole cluster (that is, cluster average usage).
The resource usage for each broker is calculated using the method
LocalBrokerData#getMaxResourceUsageWithWeight.Historical observations are included in the running average based on the broker's setting for
loadBalancerHistoryResourcePercentage.
ThresholdShedder compares each broker's average resource usage (based on current and historical resource usage) to the cluster average usage:
a. If a broker's resource usage is greater than the cluster average usage plus the configured threshold, ThresholdShedder proposes removing enough bundles to bring the unloaded broker 5% below the cluster average usage. Note that recently unloaded bundles are not unloaded again.
b. If a broker's resource usage is smaller than the cluster average usage, or smaller than the cluster average usage plus the configured threshold, no bundle will be unloaded.
For example, assume that you have 3 brokers and each broker’s average usage is as below.
| Broker name | Broker's average usage |
|---|---|
| broker1 | 40% |
| broker2 | 10% |
| broker3 | 10% |
So the cluster average usage is 20% = (40% + 10% + 10%) / 3.
If you set the threshold (loadBalancerBrokerThresholdShedderPercentage) to 10%,
then only broker1's certain bundles get unloaded, because the broker1's resource usage (40%) is greater than the sum (30%) of the cluster average usage (20%) plus configured threshold (10%).
UniformLoadShedder
UniformLoadShedder strategy distributes load uniformly across all brokers. It checks the load difference between the broker with the highest load and the broker with the lowest load. If the difference is higher than configured thresholds, either message rate (controlled by)loadBalancerMsgRateDifferenceShedderThreshold or throughput (controlled by loadBalancerMsgThroughputMultiplierDifferenceShedderThreshold), then it finds out bundles that can be unloaded to distribute traffic evenly across all brokers.

For implementation details, see PR-12902: add uniform load shedder strategy to distribute traffic uniformly across brokers.
TransferShedder
TransferShedder strategy unloads bundles from the highest load brokers to the lowest load brokers until all of the following are true:
The standard deviation of the broker load distribution is below the configured threshold (loadBalancerBrokerLoadTargetStd, default value is 0.25).
There are no significant underloaded brokers.
No broker receives 0 traffic.
No broker's load < avgLoad * min(0.5, loadBalancerBrokerLoadTargetStd / 2)
There is no significant overloaded brokers
- No broker’s load > loadBalancerBrokerOverloadedThresholdPercentage && load > avgLoad + loadBalancerBrokerLoadTargetStd
Pulsar introduced TransferShedder to utilize the bundle transfer protocol from the extensible load balancer. With this bundle transfer protocol, the bundle ownership can be gracefully transferred from the source broker to the destination broker. This means that TransferShedder pre-assigns the destination brokers at the unloading time instead of client lookups. Hence, after unloading, clients can bypass the assignment process as the new owner is already assigned.
For implementation details, see PIP-220: TransferShedder.
Related topics
To get a comprehensive understanding and discover the key insights, see Broker load balancing | Overview.
To discover different usage scenarios, see Broker load balancing | Use cases.
To explore functionalities, see Broker load balancing | Features.
To understand advantages, see Broker load balancing | Benefits.
To review various versions of broker load balancers, see Broker load balancing | Types.
To get up quickly, see Broker load balancing | Quick start.
To migrate one broker load balancer type to another, see Broker load balancing | Migration.